Примечание: Новую редакцию книги рекомендуется читать по этому адресу:
http://alfate.fatal.ru/Mag_rasum.pdf
.
Из-за сложного форматирования текста и неудобства печати, публикация в формате *.html более не редактируется.
ДВЕ СТОРОНЫ
РУССКОГО ЯЗЫКА
В предыдущем разделе были изложены концепции , на основе которых можно приступить к поиску новой системы координат , в которую бы смогла вписаться какая-то часть русского языка . Разумеется , о полном описании русского языка , с его сотнями тысяч слов и фраз , в новой системе координат речь пока не идёт .
Сначала нужно выделить
несколько критериев , с помощью которых можно зафиксировать следы "процессинга" слов и фраз
русского языка подсознанием . Для разума таким критерием является
рациональность ( рассудочное , разумно обоснованное , разумное начало ) . С
помощью этого критерия можно отыскивать ошибочные фразы в русском языке или ,
как нами было обосновано , информационный шум ( иррациональное ) . В качестве
другого критерия можно выделить особенность русского языка связанную с
усвоением словесной информации . В русском языке довольно много слов и фраз ,
которые можно понимать или в прямом смысле
(значения слов соответствуют
основному смыслу) , или в переносном , косвенном смысле ( значения слов не
соответствуют основному смыслу , часто общий смысл противоположен или не связан
с обычным значением слов ) . В принципе
второй критерий скорее отображает особенности мышления русско-язычного человека
при обработке словесной информации , так как слова при этом не меняют буквенный
состав . Возможность трактовать (интерпретировать ) фразы русского языка в двух
смыслах даёт нам и две стороны русского языка , которые можно противопоставить
друг другу .Это значит , что нами будет сделана попытка получить два описания
обычной реальности : одно - с помощью слов и фраз русского языка в прямом
смысле их значений , второе - с помощью этих же слов и фраз в переносном ,
косвенном смысле . Русский язык , как и другие языки , не только средство
общения , но и средство для описания обычной реальности .Сам по себе , такой
подход уже накладывает ограничения на его использование , так как не все слова
и фразы русского языка имеют две смысловых интерпретации .Тем не менее , мы
сделаем ещё один этап "процессинга" , чтобы уменьшить количество
подвергнутых анализу слов и фраз , и будем рассматривать в основном те слова и
фразы , которые находятся в постоянном употреблении в "массовом
сознании" русско-язычного населения , или , в терминологии
программирования ЭВМ , эти слова и фразы находятся в оперативной памяти
населения .Делая анализ слов и фраз в этой системе координат , нужно понимать ,
что это не единственно возможный способ сопоставления словесной информации при
её восприятии и усвоении .
Другой способ также частично
основывается на особенности восприятия и усвоения словесной информации с
помощью слуха . При восприятии информации с помощью слуха нам часто слышатся не
те буквы , которые находятся в составе слов при их написании ( точнее будет
сказать , что данный эффект возникает при небрежном произношении слов ) .
Например , пишем "вода" ,
слышим "вада" , или пишем "нож" , слышим "нош" и
т.д . Такое явление и было взято за основу
в ещё одной системе координат . При этом также учитывалась обнаруженная
структурная аналогия между структурой русского алфавита и химической структурой
молекулы информационной РНК , которая будет рассмотрена в разделе
"Специальная часть" . На основе этой аналогии было предположено , что
с буквами русского языка в словах во время " процессинга "
подсознанием может происходить явление аналогичное мутациям в молекулах ДНК и
РНК ( мутация , на молекулярном уровне
, выражается в замене какой-либо части молекулы ДНК или РНК на другой
химический агент , который впоследствии обуславливает передачу искажённой
информации ) .На словесном уровне , мутации будет соответствовать замена букв в
словах , но не произвольно любых букв (иначе передача информации станет невозможной
) , а подчиняющаяся определённым правилам .
Теперь остановимся на правилах
замены букв в этой системе координат . Обычно , в разговоре , слышатся замены
букв : гласные - "О" на
"А" , "Я" на "А", "Е" на "И"
, "Ё" на "О", "Е" на "Э" , "Ю" на "У",
"Й" на "И" , "И" на "Ы" ; согласные -
"Б" на "П" , "Г" на "Х" или
"К" , "Д" на
"Т" , "З" на "С", "В" на
"Ф" , "Ж" на "Ш" . Обычно указанные замены букв
происходят в середине или в конце слов . Предварительный анализ слов в такой
системе координат показал необходимость некоторого расширения приведённого
правила замен букв ( мы ведь пытаемся
подобрать систему координат, чтобы получить связное описание обычной реальности
и не обязаны строго соблюдать отмеченные выше особенности восприятия слов на
слух. Эта особенность была только начальным толчком в понимании , как нужно
создавать новую систему координат ) . Расширение правил заключается в следующем
:
1. Если буквы взаимозаменяемы ,
то можно это делать и в начале слов .
2. Заменять буквы можно в любой
последовательности . То есть не только "Б"
на "П" или "Д" на "Т" , но и наоборот
"П" на "Б" или "Т" на "Д" . Тогда ряд
взаимозаменяемых согласных букв будет выглядеть так :
"Б"Û "П" , "Г" Û "Х" Û "К" , "Д" Û "Т" , "З" Û"С" , "В" Û"Ф" , "Ж"Û "Ш" .
3. Все гласные буквы
взаимозаменяемы .
Если объединить , разбитые на
взаимозаменяемые пары , гласные буквы в одну цепочку , то можно видеть , что,
казалось бы , не похожие по звучанию буквы могут быть заменены между собой
через промежуточные взаимозаменяемые буквосочетания :
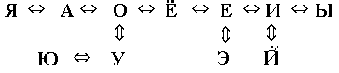
Как следует из этого ряда
взаимозаменяемости гласных букв ,
чтобы произошла замена , скажем , "А" на "И" , должны осуществиться сначала промежуточные замены
: "А" на "О",
затем "О" на "Ё" , затем "Ё" на "Е" и
далее "Е" на "И" . То есть , вводя такое правило ,
предполагается , что информация проходит несколько этапов трансляции и
перекодирования , прежде чем достигнет сознания , и на каждом этапе возможно
возникновение ошибки . На молекулярном уровне так и происходит : с молекулы
ДНК информация переходит на молекулу
иРНК , с молекулы иРНК в рибосоме
клетки на синтезирующийся полипептид ( предбелок ) . В этом примере показаны
этапы трансляции и перекодирования информации
при передаче информации от молекулы ДНК . Однако , сама молекула ДНК уже может содержать ошибочную информацию
вследствие мутаций из-за каких-то нарушений при делении клетки или действия
радиации (не все мутации обязательно заканчиваются гибелью клетки ) . Таким образом
, учитывая многоуровневое строение человека , вполне возможно многоэтапное
прохождение информации с возникновением ошибок .При этом вероятность замены
"А" на "И" за один "цикл" прохождения информации
невелика , но со временем , по мере накопления ошибок на промежуточных этапах
передачи информации , эта вероятность всё более увеличивается .
4. Мягкий знак "Ь" и
твёрдый знак "Ъ" можно не учитывать при анализах слов , так как они
несут в словах в основном функцию знака препинания ( разделения ) , а при
словообразовании , склонении или спряжении слов часто исчезают ( Русь - русский ) .
5. Анализировать нужно
неизменяемую часть слова . К неизменяемой части слова относится та часть слова
, которая не изменяется при склонении, спряжении слова , а также при
образовании из него прилагательных и глаголов . Это совпадает с понятием
"корень" слова .
6. В русском языке слова
пишутся и читаются слева направо , но существуют языки арабских стран ,
еврейский язык , в которых слова пишутся и читаются справа налево . Применение
такого явления к словам русского языка , чтения их справа налево , позволяет
ввести ещё одну возможность противопоставления сторон , условно назовём ,
чтение слева и чтение справа . Это правило можно считать также логическим развитием пунктов
2 и 3 , когда замена букв на слух происходит в одном направлении , но мы
учитываем возможность замены букв и в обратном направлении .
Таковы основные правила , которые будут использоваться при анализе
слов и фраз . Правила анализа заведомо составлены в сокращённом виде , чтобы
впоследствии можно было при необходимости
их добавлять по мере роста понимания , так как они являются только
"арифметикой" или "алгеброй" по отношению к русскому языку
, а ведь должно , по аналогии с математикой , существовать и
"дифференциальное" , и "интегральное" исчисление в
отношении слов и фраз русского языка . По мере развёртывания исследования они
будут подвергаться определённой коррекции , так как на начальном этапе трудно понять существующие ограничения на
использование этих правил . Кроме того , некоторые правила или аналитические
способы оперирования со словами будут рассмотрены уже в ходе изложения
результатов исследования .
НАЧАЛО НОВОЙ КЛАССИФИКАЦИИ РУССКОГО ЯЗЫКА
Располагая набором правил , мы оказались перед огромным
массивом слов . Возникает вопрос , с какого слова начать ? Существует несколько "входов" в
этот массив ( объёмный лабиринт ) слов
, в зависимости от выбора исследователя
.
Для русско-язычного человека таким словом может
быть - РУСЬ ( РОСЬ ) , как
давшее название и государству , и русскому языку . С помощью
имеющихся правил попытаемся извлечь дополнительную информацию ( общепринятая
информация , которую несёт данное слово , содержится в предыдущем предложении )
. Воспользуемся правилами замен букв и
удаления мягкого знака :
РУСЬ Û РАЗ (
1 )
Получили слово "раз" . Оно имеет несколько
значений и мы выберем только те , в которых слово "раз" является
самостоятельным ( подробнее см. С.И.Ожегов и др. " Толковый словарь
русского языка" [1] ) . Основным значением слова "раз" является
значение единицы счёта ( раз , два раза , три раза ... ) .
Отметим , что это значение является
прямым смыслом слова . В отличие от значений
во фразе "в самый раз ( разг.) - 1) во-время, в нужный
момент; 2) впору , как раз по размеру" ( С.И.Ожегов и др.[1]) . В этой
фразе и в подобных ей ( "в другой раз ..." , " в
прошлый раз ..." ) слово "раз" имеет значение временного
отрезка , промежутка времени , и в этом значении несёт косвенный смысл .
Другой возможный вариант
изменения слова " РУСЬ" :
РУСЬ Û РИС
(1а)
Рис
является пищевым продуктом , который был введён в массовое употребление русскоязычным населением относительно
недавно .Такой вариант анализа , очевидно , даёт мало информации , интересующей
нас в первую очередь ( нам важно знать, что происходит с человеческим
сообществом в стране и в мире, и почему ) . Поэтому этот вариант будем считать
побочным или , если выражаться образно , этот вариант является ответвлением от
основного канала словесного лабиринта .
Таких ответвлений будет множество и в каждом случае нам придётся делать выбор в
пользу того или иного варианта анализа , то есть осуществлять
"процессинг" , иначе нам не найти ответы на поставленные вопросы
Также к побочным отнесён
вариант :
РУСЬ Û РЫСЬ (1б)
Это не значит , что все побочные варианты анализа
ошибочны . Как известно , в лабиринтах не бывает прямых путей и вполне
возможно , что какой-либо из побочных вариантов анализа впоследствии дополнит
информацию , полученную в каком-либо из основных вариантов ( не забудем , что
входов в лабиринт несколько и значит, есть изначально несколько путей ) .
Теперь рассмотрим слово "РУСЬ"
в обратной системе координат ( чтение справа ) по тем же правилам .
РУСЬ ï ЬСУР
Û СОР
Û СЫР
Û СЭР
(2)
Получилось три варианта .
Рассматриваются только те варианты , в которых получились самостоятельные общеупотребительные слова .
Слово "сор" обычно обозначает мусор , грязь, то есть ненужную часть чего-либо , помеху , противоположность чистоты . Слово
"сыр" обозначает пищевой продукт , получающийся из молока . Слово
"сэр" является заимствованным иностранным словом , "в
англоязычных странах : почтительное обращение к мужчине" ( С.И . Ожегов и
др.[1] ) . Из этих вариантов отметим ,
что " сор ", являясь помехой для гармонического восприятия
реальности , родственен по функциям шуму ,то есть их можно объединить в
одну иерархическую группу по этому признаку . Два других варианта пока не с чем
сопоставить или чему-либо противопоставить .
Можно поступить как в
математике и логике : противопоставить 1 и 0 , соответственно " да "
и " нет ", и получить, таким образом, недостающие для сопоставления
слова , " точки отсчёта ", "ключевые" слова . Это будет ещё
один вход в лабиринт слов .
Воспользуемся таким методом ,
но с учётом нашей системы координат . Сравнение вариантов истолкования
информации при анализе слова " РУСЬ " при чтении слева , с учётом общепринятой информации , и при
чтении справа , позволяет выделить
чтение слева как несущее положительную информацию , соответственно ,
чтение справа как несущее "сорную" информацию или информацию ,
имеющую в себе шумовую компоненту , то есть ложную информацию .
Тогда в нашей системе координат чтение
слов слева направо будет соответствовать значению "да", а
чтение справа налево значению " нет ". По результатам предварительного анализа слов и фраз будет лучше это обозначить словами :"
верно " - " неверно " ( в числовом выражении чтение слева
- 1 , а чтение справа - 0,5 , но не ноль , так как ноль по смыслу -
ничто и значит, не может служить противопоставлением в этой системе координат . В нашей системе координат даже ложь заключает в себе
определённую информацию , которую можно подвергнуть анализу и сделать
определённый вывод ) . стр .17
Ранее нами была рассмотрена иерархическая группа
понятий , обозначающих неверную информацию , под общим обозначением
"ШУМ". Тогда в нашей системе координат слово "ШУМ" будет
соответствовать прочтению этого слова справа налево (с учётом выражения (2) и
его анализа) , как выражающее неверную информацию . Тогда верную информацию
несёт слово обратное слову " ШУМ " .
ШУМ
ï МУШ Û МУЖ
Теперь запишем этот вывод в
привычном для нашей системы координат виде , чтобы было более понятно .
МУЖ ï ЖУМ
Û ШУМ
(3)
Здесь и далее будем
обозначать чтение слева полужирным
шрифтом , а чтение справа обычным , будем также пользоваться словосочетаниями :
прямое чтение (слева) и обратное чтение (справа).
Проанализируем полученные
выражения . Слово " муж " имеет два значения: 1) " муж ", как выражение мужского качества в
противоположность женскому качеству ; 2) "муж ", как супруг женщины .
Первый вариант является прямым смыслом слова "муж " , второй вариант
является косвенным смыслом этого слова . Так как в нашей системе
координат противопоставление выражается в виде чтения слов слева направо и
справа налево , то слова, попадающие в левую часть выражений (или
соответственно в правую часть выражений) будут наделять соответствующую сторону
присущими им по смыслу характеристиками . С учётом выражений (1) - (3)
левая их часть получила характеристики мужского качества (мужского рода) и
счёта (времени) , а правая их часть получила характеристики женского качества
(женского рода) , (сыр получают из
молока , продукта с женским качеством ) и шумовой информации .
Таким образом , у нас появилась ещё одна возможность
противопоставления ( ещё одна координата ) : мужского и женского качеств , но не
только в виде разных слов ( мужской - женский ) , а в виде чтения слов слева
направо ( мужской ) и чтения слов справа налево ( женский ) с учётом
вышеизложенных правил анализа слов . В
подтвержденье можно привести слова "жеманиться
", "жеманная "
обычно относимые к женскому поведению . Корнем в этих словах является "жем ", которое
можно рассматривать как производное от слова "шум ", то есть обратное
слову "муж " .
Продолжим исследование группы
слов "ШУМ" . К этой группе можно отнести слово "ор" (орать)
, обозначающее громкий крик ,то есть шум . Осуществим преобразование с этим
словом аналогичное тому , которое проделали со словом " шум " . То
есть будем считать , что слово "ор" - синоним слова "шум"-
является прочтением справа . Тогда
ОР ï РА
или в привычном виде
РА Û РАй ï АР
Û ОР Û
ЕР Û
ЯР (4)
(в раю)
" РА " является богом Солнца в древнем Египте ,
то есть общепринятая информация , содержащаяся в этом слове при чтении слева
направо, несомненно, положительна и не требует особых разъяснений , как и слово
"рай". В русском языке слово "РА" является
самостоятельным только в этом значении
. Наша система координат позволяет легко обнаружить другие однокоренные слова :
"рука" ( ручной ) , "река"
( речной ) .
РУ
Û РА Û РЕ ....... (4а)
(рука) (река)
Отметим , что последнее
выражение (4а) наглядно объясняет то , что у реки есть рукав (ответвление
от главного русла реки). Рукав ассоциируется в прямом смысле с рукой , в
переносном смысле с рекой . Как видим , однокоренные слова "рука" и
"река", происходящие от слова "РА" , также несут
положительную или нейтральную информацию .
Чтение этих слов справа налево
в нашей системе координат также даёт правую часть
выражения (4) . Слово "ар" является единицей земельной площади . Словом "еръ" в кириллице называлась
буква "Ъ" . Буква "Ь" называлась "ерь" , буква
"Ы" называлась "еры" . Энциклопедия "РУССКИЙ ЯЗЫК
"[2] указывает , что буква "Ы" "произошла из составного
знака ъ+I (еръ+и)". Действительно , при сравнении с кириллическим
алфавитом становится видно , что ранее "еры" изображалась как
"ЪI" . Это важный момент , подробнее об этом будет сказано при
анализе русского алфавита .
На основе выражения (4) в нашей
системе координат
можно получить подтверждение верности расположения левой и правой частей этой
записи . Кроме приведённых в выражении (4) слов , для правой части существуют
ещё несколько однокоренных слов . Слова "юрист", "юридический"
происходят от латинского слова "de jure" (дэ юрэ) и
обозначают в русском языке "право" в законодательном смысле . Это значение
является косвенным смыслом слова "право" . В прямом смысле слово
"право" обозначает сторону ,
расположенную ближе к правой руке человека , противоположна левой стороне .
Такое деление на левую и правую стороны
окружающей реальности является условным и базируется на субъективной системе
координат , отображающей внешне симметричное строение человеческого тела .
Однако , здесь следует учитывать , что любая система координат является
субъективной , так как учитывает только небольшую часть свойств , характеризующих
то или иное явление (в этом проявляется "процессинг") .
Наша
система координат является своего рода классификатором ,
позволяющим создать новую классификацию слов русского языка по ряду признаков
(причём классификация слов русского языка происходит подобно выводу
математических выражений ) , отличающуюся от уже существующей , основанной на
произвольно выбранных характеристиках .Традиционное отнесение слов русского
языка к мужскому , женскому и среднему роду (заметьте, без какого-либо обоснования
возникновения такой классификации ) основано на имеющихся окончаниях слов (он
, она , оно) , причём
совершенно не учитывается смысл этих слов . В нашей
системе координат слово "шум" наделено женским качеством (относится
к женскому роду) , а при обычной
классификации это слово отнесено к мужскому роду . С помощью нашей
системы координат получает наглядное объяснение существование в русском языке
некоторых фраз . Например , фраза "женщина всегда права(-о)"
совпадает со сделанным выше выводом о возникновении при обратном чтении слов
характеристик : женского и права ( в законодательном смысле ) . Отсюда же
вытекает общепринятое наделение
"левого" характеристикой противозаконного (в косвенном ,
переносном смысле , также как и "право" используется в переносном
смысле ) .
Название применяемой
системы координат происходит от слова - "наш" и это не случайно .
НАШ Û
НОЖ ï ЖОН
Û ЖЕН
(5)
(женский)
Чтобы более чётко показать в
названии мужское качество ( в прямом смысле) теперь будем называть применяемую
систему координат - Наш классификатор слов . Отнесение слова "нож" к левой части выражения (5) происходит не
только по правилам замен букв , но и вследствие выявляющейся связи с выражением
(4) . Действительно , функция ножа состоит в резании чего-либо . Корнем слова
"резанье" (режет) является " РЕ
" производное от слова "РА".
Вернёмся к выражению (4) .
Слово "яр" обозначает глубокий овраг , во втором значении - крутой
берег , обрыв . От этого слова существует переход к другому слову группы
"ШУМ " через слово "ров " по смыслу близкое со словом
"яр" . Таким словом является "рёв"- протяжный крик
животного или шум . Проделаем с этим словом уже привычные преобразования и
получим :
ВЕР ï РЁВ (6)
(верить)
При формальном рассмотрении в
левую часть Нашего классификатора попадают
слова и с отрицательной информацией ("вор")( в смысле оценки содержащейся в слове "вор"
информации в пределах "хорошо -
плохо") . Сейчас мы не будем вдаваться в тонкости обсуждения этого вывода
и некоторых других неоднозначных выводов в последующих примерах , применяя правила
анализа слов большей частью формально . Это позволит не усложнять анализ на
начальном этапе , пока не наберётся достаточного количества проанализированных
слов для сопоставления , и просто
отметим , что в случае включения в выражение (6) слова "вор" , оно
вполне согласуется с ранее сделанным выводом о том , что правая часть выражения
(4) содержит в себе характеристику правопорядка .Тем не менее, слово
"вор" как и другие однокоренные слова, попадающие в соответствии с
правилами в левую часть выражения (6), отнесены к побочным ветвям словесного лабиринта .
Корень "вер"
лежит в основе слов "верить" , "доверчивость" , которые
являются общепризнанной характеристикой "русской души" и несут прямой
смысл , косвенный же смысл несёт слово
"вера" в религиозном значении и женское имя .
Продолжим анализ . К группе
слов "ШУМ " относится и слово "гам" обозначающее "
беспорядочный гул голосов , крики
" ( С.И. Ожегов и др.[1]) . Кроме того , в русском языке существует
устойчивое словосочетание "шум и гам" явно указывающее на то , что
эти слова близки по своему смыслу . Поэтому
МИГ Û МАГ ï ГАМ
Û ХАМ (7)
"Хам - грубый , наглый
человек " (С.И.Ожегов и др.[1]) , по более точному определению В.И.Даля
[3] , хам назван:холопом , лакеем , подлым , неучем . Здесь Наш
классификатор указывает на связь хама с шумом , что обычно и
наблюдается в поведении подобных людей( можно отметить также прямую связь хама
с женским началом , так как хам обычно ругается матом: мат Û мать . По С.И .Ожегову , "маг"- человек , владеющий тайнами
магии , а "магия" - совокупность считающихся чудодейственными обрядов
и заклинаний , призванных воздействовать на природу , людей , животных и богов
.Такое определение не может быть признано верным , так как под такое же
определение подпадает и "шаманизм ". Наш
классификатор относит шаманов (шам-ан) к группе слов
" ШУМ ". Хотя в слове "шаман" неизменяемая часть слова охватывает целиком это слово (шаманить)
, оно попадает в группу слов " ШУМ " не только как исключение из
правил , но и по характеру поведения во время ритуалов , что ставит
"шаманизм" в один ряд с религией , а религия , как будет показано
позже , проявляет чёткую связь с правой частью выражений . Кстати , слово
"жеманиться" можно рассматривать и как происходящее от слова
"шаман", и то и другое
характеризуют неестественное поведение .
На этом примере становится
понятно , что бездумное следование однажды установленным правилам может завести
в тупик , если не учитывать дополнительные параметры и разумное начало .
Сейчас не стоит давать новое
определение "магии" и "мага" , пока не уясним себе весь
набор параметров , характеризующих эти слова с помощью Нашего
классификатора .
Продолжим анализ левой части
выражения (7) . Слово "миг" обозначает кратчайший промежуток времени
. Слово "раз" , как отмечено выше , также по смыслу несёт информацию
о времени . Следовательно , верно определено положение этих слов в Нашем
классификаторе . Выявлена также связь мага и времени . В левой части
выражения (7) должны также находиться , в соответствии с правилами , и
однокоренные слова "мак" , "мех", а в правой слова
"ком" , "кум". На данном этапе эти варианты отнесены к
побочным ветвям словесного лабиринта , хотя не исключено , что на каком-то
этапе анализа эти слова будут востребованы .
Другие слова :
"ошибка" , "ложь " , "галлюцинация " , отнесенные
к группе слов " ШУМ " , в Нашем
классификаторе пока не могут быть однозначно проанализированы, хотя ,
конечно , по заключённому в них смыслу относятся к правой части выражений , а
слово "ложь" (лжи) , корнем в котором является буква
"л", вообще не поддаётся анализу в Нашем
классификаторе , который классифицирует корни слов по
содержащемуся в них смыслу , а буква "л" словом не является .
Поэтому , пока они анализироваться не будут .
продолжение